Rethinking the role of frames for SE(3)-invariant crystal structure modeling
ICLR 2025'%3e%3cmetadata%20id='metadata16'%3e%3crdf:RDF%3e%3ccc:Work%20rdf:about=''%3e%3cdc:format%3eimage/svg+xml%3c/dc:format%3e%3cdc:type%20rdf:resource='http://purl.org/dc/dcmitype/StillImage'%20/%3e%3cdc:title%3e%3c/dc:title%3e%3c/cc:Work%3e%3c/rdf:RDF%3e%3c/metadata%3e%3cdefs%20id='defs14'%3e%3cclipPath%20clipPathUnits='userSpaceOnUse'%20id='clipPath28'%3e%3cpath%20d='M%200,1080%20H%201920%20V%200%20H%200%20Z'%20id='path26'%20/%3e%3c/clipPath%3e%3cclipPath%20clipPathUnits='userSpaceOnUse'%20id='clipPath128'%3e%3cpath%20d='M%200,1080%20H%201920%20V%200%20H%200%20Z'%20id='path126'%20/%3e%3c/clipPath%3e%3cclipPath%20clipPathUnits='userSpaceOnUse'%20id='clipPath18'%3e%3cpath%20d='M%200,1080%20H%201920%20V%200%20H%200%20Z'%20id='path16'%20/%3e%3c/clipPath%3e%3c/defs%3e%3csodipodi:namedview%20pagecolor='%23ffffff'%20bordercolor='%23666666'%20borderopacity='1'%20objecttolerance='10'%20gridtolerance='10'%20guidetolerance='10'%20inkscape:pageopacity='0'%20inkscape:pageshadow='2'%20inkscape:window-width='1440'%20inkscape:window-height='914'%20id='namedview12'%20showgrid='false'%20fit-margin-top='0'%20fit-margin-left='0'%20fit-margin-right='0'%20fit-margin-bottom='0'%20inkscape:zoom='0.434375'%20inkscape:cx='484.54599'%20inkscape:cy='90.825431'%20inkscape:window-x='-6'%20inkscape:window-y='-6'%20inkscape:window-maximized='1'%20inkscape:current-layer='g18'%20/%3e%3cg%20id='g18'%20inkscape:groupmode='layer'%20inkscape:label='SINICX_Logo_2024_06%20(1)'%20transform='matrix(1.3333333,0,0,-1.3333333,-871.99998,786.66665)'%3e%3cg%20id='g122'%3e%3cg%20id='g124'%20clip-path='url(%23clipPath128)'%3e%3cg%20id='g130'%20transform='translate(1236,540)'%3e%3cpath%20d='m%200,0%20c%200,14.984%209.494,26.752%2030,27.5%20l%20-2,20%20C%20-3,45.572%20-22,25%20-22,0%20c%200,-25%2019,-45.572%2050,-47.5%20l%202,20%20C%209.494,-26.752%200,-14.984%200,0%20m%20-74,47.5%20-2,-20%20c%2020.506,-0.748%2030,-12.516%2030,-27.5%200,-14.984%20-9.494,-26.752%20-30,-27.5%20l%202,-20%20c%2031,1.928%2050,22.5%2050,47.5%200,25%20-19,45.572%20-50,47.5%20M%20-158,-50%20c%2010.163,0%2023.222,1.516%2035.5,7.5%20l%201,21.5%20c%20-15.419,-7.98%20-24.349,-9.5%20-34,-9.5%20-22.885,0%20-35,10.715%20-35,30.5%200,20.281%2011.498,31%2033.5,31%2010.539,0%2019.19,-2.25%2033.5,-10%20l%20-1,21%20c%20-12.951,6.497%20-23.605,8%20-33.5,8%20-34.125,0%20-55.5,-19.341%20-55.5,-50%200,-30.784%2021.128,-50%2055.5,-50%20m%20-103.5,2.5%20h%2022%20v%2095%20h%20-22%20z%20M%20-536,-50%20c%2027.127,0%2042,11.809%2042,30.326%200,23.018%20-24.358,28.393%20-43.5,31.7%20-13.347,2.306%20-23,4.28%20-23,10.8%200,5.697%206.895,8.092%2021.673,8.092%2013.023,0%2027.965,-2.697%2040.327,-7.592%20l%20-1,21%20C%20-515.737,49.045%20-526.907,50%20-539,50%20c%20-26.578,0%20-43,-10.415%20-43,-27.122%200,-22.856%2023.488,-27.807%2042.038,-31.027%2013.246,-2.343%2024.462,-4.36%2024.462,-12.006%200,-8.118%20-10.957,-10.019%20-20.5,-10.019%20-15.487,0%20-27.243,4.543%20-45.5,13.674%20l%201,-22.5%20c%2015.24,-7.948%2031.788,-11%2044.5,-11%20m%2077.5,2.5%20h%2022%20v%2095%20h%20-22%20z%20m%2060.5,95%20h%2021%20l%2055,-63.5%20v%2063.5%20h%2022%20v%20-95%20h%20-21%20L%20-376,16%20v%20-63.5%20h%20-22%20z'%20style='fill:%23000000;fill-opacity:1;fill-rule:nonzero;stroke:none'%20id='path132'%20/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)

TL;DR To make a GNN invariant to rotations, let's standardize the orientations of local atomic environments represented by internal self-attention weights, instead of directly standardizing the global structure.
Overview
Crystal structure modeling with graph neural networks is essential for various applications in materials informatics, and capturing SE(3)-invariant geometric features is a fundamental requirement for these networks. A straightforward approach is to model with orientation-standardized structures through structure-aligned coordinate systems, or ‟frames.” However, unlike molecules, determining frames for crystal structures is challenging due to their infinite and highly symmetric nature. In particular, existing methods rely on a statically fixed frame for each structure, determined solely by its structural information, regardless of the task under consideration. Here, we rethink the role of frames, questioning whether such simplistic alignment with the structure is sufficient, and propose the concept of dynamic frames. While accommodating the infinite and symmetric nature of crystals, these frames provide each atom with a dynamic view of its local environment, focusing on actively interacting atoms. We demonstrate this concept by utilizing the attention mechanism in a recent transformer-based crystal encoder, resulting in a new architecture called CrystalFramer. Extensive experiments show that CrystalFramer outperforms conventional frames and existing crystal encoders in various crystal property prediction tasks.
Problem
Crystal structure
Crystal structures are periodic arrangements of atoms in 3D space, serving as the source codes for diverse materials, such as permanent magnets, battery materials, and superconductors.

Crystal structure in 2D space
A crystal structure is typically described by its repeatable 3D slice called a unit cell. We assume a unit cell consisting of atoms and denote it as :
- : the species (atomic numbers) of unit cell atoms.
- : the 3D Cartesian coordinates of unit cell atoms.
- : lattice vectors that define periodic unit-cell translations in 3D space.
By tiling the unit cell to fill 3D space, the species and positions of atoms in the crystal structure are determined as follows.
Here, we use to denote the -th atom in the unit cell, and use to denote its duplicate by the 3D translation: . We use and similarly.
SE(3)-invariant structural modeling
We consider the problem of estimating the physical state of a given crystal structure, assuming that the state remains invariant under rigid transformations (i.e., rotations and translations). Such a state typically corresponds to material properties, such as formation energy and bandgap.
We represent the state of a crystal structure by a set of abstract atom-wise state features for the unit-cell atoms:
As input to a graph neural network (GNN), these features are usually initialized via atom embeddings:
which only symbolically represent atomic species. They are then evolved through message-passing layers
to eventually reflect the atomic states appropriate for a target task.
Challenges in SE(3)-invariant GNNs
There are several approaches to ensuring SE(3) invariance in GNNs:
- Invariant features: Leveraging inherently invariant geometric features, such as interatomic distances and angles between triplets , ensures SE(3) invariance. However, fully distance-based models have limited expressive power, and incorporating three-body interactions significantly increases computational complexity.
- Frames: Another straightforward approach is to standardize the orientation of a given structure through a structure-aligned coordinate system called a frame. However, determining frames for crystal structures is challenging due to their infinite and highly symmetric nature.
We explore a new frame-based methodology to incorporate richer yet invariant structural information beyond distances.
Ideas
What is the role of frames?
Surely, it is to standardize the orientations of given structures so that GNN models can directly exploit 3D coordinate information as invariant geometric features.
── Is that all?
Let’s dig deeper into how frames work in a GNN, whose message-passing layers are assumed to include the following general operation:
This equation describes that the state of each unit-cell atom is updated by receiving abstract influences or ‟messages”, , from atoms in the structure, weighted by scalars . In recent transformer models, these weights are determined dynamically via self-attention mechanisms.
Distance-based GNNs ensure SE(3) invariance by simply formulating with the interatomic distance, , as follows:
The role of frames is to offer, for the design of the message function , more informative invariant features beyond the distance through a structure-aligned coordinate system , as follows:
where the frame-projected relative position remains invariant under global rotations and translations for the crystal structure .
Dynamic frames
Given that the end-users of frames are the message functions in GNNs, shouldn't we tailor a frame for each message function in each layer so that the function receives a better-normalized structure?
── We pursue this idea by introducing the concept of dynamic frames.
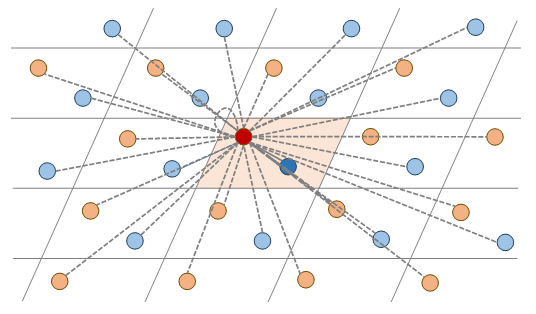
In each message passing layer, the target atom receives more influences from atoms with larger weights , and no influence from atoms with zero weights. This means that, when updating the state of atom , this atom has its own partial and local view of the structure through weights acting as a mask on the structure.

Dynamic frame in 2D space
As a dynamic frame, we therefore construct an atom-wise frame for each target atom by using this masked view of the structure with weights , as follows:
Typically, we define an orthonormal basis as a frame, where the first and second axes point towards the primary and secondary influential directions of interatomic interactions. (See the paper for detailed definitions.)
This dynamic frame is then used to project the relative position vectors in order to derive the messages for the target atom , as follows:
Importantly, our dynamic frames are constructed with the entire structure , rather than with a specific unit-cell representation . Thus, our dynamic frames are invariant under the unit-cell variations within the same crystal structure.
CrystalFramer
We demonstrate the proposed concept of dynamic frames by utilizing the Crystalformer architecture (Taniai et al., ICLR 2024). Crystalformer employs the standard softmax self-attention for message passing, which is formulated as infinitely connected distance-decay attention as follows:
Here, query , key , and value are linear projections of the current state . Scalar is the normalizer of softmax attention weights. Vector is a geometric relative position encoding for atoms and .
Originally, simply encodes the scalar distance via a linear projection of Gaussian basis functions (GBFs). In this work, we enhance the model's expressive power by incorporating frame-based geometric features into the Crystalformer's relative position encoding . This results in a new architecture CrystalFramer.
Frame-based invariant features
Given the unit direction vector , we obtain its invariant representation , where the -th component represents the cosine of the angle between the -th axis and the direction:
Using GBFs as a mapping from a scalar to a vector, we linearly combine the distance-based and three angle-based edge features, as follows:
This as a whole essentially encodes the 3D relative position vector, .
Architecture
Below is the architecture of CrystalFramer, where we have introduced dynamic frame construction and frame-based edge features, as highlighted in the figure.

CrystalFramer architecture
Given the multi-head self-attention mechanism, we dynamically construct a frame for each target atom, head, and layer during the self-attention operation.
Property Prediction Benchmarks
We evaluated the performance of CrystalFramer using two types of dynamic frames: weighted PCA frames and max frames. We compared these with existing crystal frames (PCA frames and lattice frames) and other state-of-the-art crystal encoders. For evaluation, we used three datasets: JARVIS (55,723 materials), Materials Project (69,239 materials), and OQMD (817,636 materials).
JARVIS dataset
| E form | E total | BG (OPT) | BG (MBJ) | E hull | |
|---|---|---|---|---|---|
| CGCNN (Xie & Grossman, 2018) | 0.063 | 0.078 | 0.20 | 0.41 | 0.17 |
| SchNet (Schütt et al., 2018) | 0.045 | 0.047 | 0.19 | 0.43 | 0.14 |
| MEGNet (Chen et al. 2019) | 0.047 | 0.058 | 0.145 | 0.34 | 0.084 |
| GATGNN (Louis et al., 2020) | 0.047 | 0.056 | 0.17 | 0.51 | 0.12 |
| M3GNet (Chen et al., 2022) | 0.039 | 0.041 | 0.145 | 0.362 | 0.095 |
| ALIGNN (Choudhary et al., 2021) | 0.0331 | 0.037 | 0.142 | 0.31 | 0.076 |
| Matformer (Yan et al., 2022) | 0.0325 | 0.035 | 0.137 | 0.30 | 0.064 |
| PotNet (Lin et al., 2023) | 0.0294 | 0.032 | 0.127 | 0.27 | 0.055 |
| eComFormer (Yan et al., 2024) | 0.0284 | 0.032 | 0.124 | 0.28 | 0.044 |
| iComFormer (Yan et al., 2024) | 0.0272 | 0.0288 | 0.122 | 0.26 | 0.047 |
| Crystalformer (Taniai et al., 2024) | 0.0306 | 0.0320 | 0.128 | 0.274 | 0.0463 |
| ─ w/ PCA frames (Duval et al., 2023) | 0.0325 | 0.0334 | 0.144 | 0.292 | 0.0568 |
| ─ w/ lattice frames (Yan et al., 2024) | 0.0302 | 0.0323 | 0.125 | 0.274 | 0.0531 |
| ─ w/ static local frames | 0.0285 | 0.0292 | 0.122 | 0.261 | 0.0444 |
| ─ w/ weighted PCA frames (proposed) | 0.0287 | 0.0305 | 0.126 | 0.279 | 0.0444 |
| ─ w/ max frames (proposed) | 0.0263 | 0.0279 | 0.117 | 0.242 | 0.0471 |
Materials Project dataset
| E form | BG | Bulk modulus | Shear modulus | |
|---|---|---|---|---|
| CGCNN (Xie & Grossman, 2018) | 0.031 | 0.292 | 0.047 | 0.077 |
| SchNet (Schütt et al., 2018) | 0.033 | 0.345 | 0.066 | 0.099 |
| MEGNet (Chen et al. 2019) | 0.030 | 0.307 | 0.060 | 0.099 |
| GATGNN (Louis et al., 2020) | 0.033 | 0.280 | 0.045 | 0.075 |
| M3GNet (Chen et al., 2022) | 0.024 | 0.247 | 0.050 | 0.087 |
| ALIGNN (Choudhary et al., 2021) | 0.022 | 0.218 | 0.051 | 0.078 |
| Matformer (Yan et al., 2022) | 0.021 | 0.211 | 0.043 | 0.073 |
| PotNet (Lin et al., 2023) | 0.0188 | 0.204 | 0.040 | 0.065 |
| eComFormer (Yan et al., 2024) | 0.0182 | 0.202 | 0.0417 | 0.0729 |
| iComFormer (Yan et al., 2024) | 0.0183 | 0.193 | 0.0380 | 0.0637 |
| Crystalformer (Taniai et al., 2024) | 0.0186 | 0.198 | 0.0377 | 0.0689 |
| ─ w/ PCA frames (Duval et al., 2023) | 0.0197 | 0.217 | 0.0424 | 0.0719 |
| ─ w/ lattice frames (Yan et al., 2024) | 0.0194 | 0.212 | 0.0389 | 0.0720 |
| ─ w/ static local frames | 0.0178 | 0.191 | 0.0354 | 0.0708 |
| ─ w/ weighted PCA frames (proposed) | 0.0197 | 0.214 | 0.0423 | 0.0715 |
| ─ w/ max frames (proposed) | 0.0172 | 0.185 | 0.0338 | 0.0677 |
OQMD dataset
| # Blocks | E form | BG | E hull | |
|---|---|---|---|---|
| Crystalformer (baseline) | 4 | 0.02115 | 0.06028 | 0.06759 |
| CrystalFramer (max frames) | 4 | 0.01871 | 0.05805 | 0.06607 |
| Crystalformer (baseline) | 8 | 0.02104 | 0.05986 | 0.06690 |
| CrystalFramer (max frames) | 8 | 0.01778 | 0.05785 | 0.06454 |
Overall, CrystalFramer significantly improves the baseline performance of CrystalFormer and outperforms most existing methods across various tasks and datasets.
Visual Analysis


Max frames capture local motiffs around the target atom, while weighted PCA frames look at the structure over broader areas. Both types of frames tend to focus on close neighbors in shallow layers and relatively distant neighbors in deeper layers.
Contact
Citation
@inproceedings{ito2025crystalframer,
title = {Rethinking the role of frames for SE(3)-invariant crystal structure modeling},
author = {Yusei Ito and
Tatsunori Taniai and
Ryo Igarashi and
Yoshitaka Ushiku and
Kanta Ono},
booktitle = {The Thirteenth International Conference on Learning Representations (ICLR 2025)},
year = {2025},
url = {https://openreview.net/forum?id=gzxDjnvBDa}
}