Can Compact Language Models Search Like Agents? Distillation-Guided Policy Optimization for Preserving Agentic RAG Capabilities
ACL 2026'%3e%3cmetadata%20id='metadata16'%3e%3crdf:RDF%3e%3ccc:Work%20rdf:about=''%3e%3cdc:format%3eimage/svg+xml%3c/dc:format%3e%3cdc:type%20rdf:resource='http://purl.org/dc/dcmitype/StillImage'%20/%3e%3cdc:title%3e%3c/dc:title%3e%3c/cc:Work%3e%3c/rdf:RDF%3e%3c/metadata%3e%3cdefs%20id='defs14'%3e%3cclipPath%20clipPathUnits='userSpaceOnUse'%20id='clipPath28'%3e%3cpath%20d='M%200,1080%20H%201920%20V%200%20H%200%20Z'%20id='path26'%20/%3e%3c/clipPath%3e%3cclipPath%20clipPathUnits='userSpaceOnUse'%20id='clipPath128'%3e%3cpath%20d='M%200,1080%20H%201920%20V%200%20H%200%20Z'%20id='path126'%20/%3e%3c/clipPath%3e%3cclipPath%20clipPathUnits='userSpaceOnUse'%20id='clipPath18'%3e%3cpath%20d='M%200,1080%20H%201920%20V%200%20H%200%20Z'%20id='path16'%20/%3e%3c/clipPath%3e%3c/defs%3e%3csodipodi:namedview%20pagecolor='%23ffffff'%20bordercolor='%23666666'%20borderopacity='1'%20objecttolerance='10'%20gridtolerance='10'%20guidetolerance='10'%20inkscape:pageopacity='0'%20inkscape:pageshadow='2'%20inkscape:window-width='1440'%20inkscape:window-height='914'%20id='namedview12'%20showgrid='false'%20fit-margin-top='0'%20fit-margin-left='0'%20fit-margin-right='0'%20fit-margin-bottom='0'%20inkscape:zoom='0.434375'%20inkscape:cx='484.54599'%20inkscape:cy='90.825431'%20inkscape:window-x='-6'%20inkscape:window-y='-6'%20inkscape:window-maximized='1'%20inkscape:current-layer='g18'%20/%3e%3cg%20id='g18'%20inkscape:groupmode='layer'%20inkscape:label='SINICX_Logo_2024_06%20(1)'%20transform='matrix(1.3333333,0,0,-1.3333333,-871.99998,786.66665)'%3e%3cg%20id='g122'%3e%3cg%20id='g124'%20clip-path='url(%23clipPath128)'%3e%3cg%20id='g130'%20transform='translate(1236,540)'%3e%3cpath%20d='m%200,0%20c%200,14.984%209.494,26.752%2030,27.5%20l%20-2,20%20C%20-3,45.572%20-22,25%20-22,0%20c%200,-25%2019,-45.572%2050,-47.5%20l%202,20%20C%209.494,-26.752%200,-14.984%200,0%20m%20-74,47.5%20-2,-20%20c%2020.506,-0.748%2030,-12.516%2030,-27.5%200,-14.984%20-9.494,-26.752%20-30,-27.5%20l%202,-20%20c%2031,1.928%2050,22.5%2050,47.5%200,25%20-19,45.572%20-50,47.5%20M%20-158,-50%20c%2010.163,0%2023.222,1.516%2035.5,7.5%20l%201,21.5%20c%20-15.419,-7.98%20-24.349,-9.5%20-34,-9.5%20-22.885,0%20-35,10.715%20-35,30.5%200,20.281%2011.498,31%2033.5,31%2010.539,0%2019.19,-2.25%2033.5,-10%20l%20-1,21%20c%20-12.951,6.497%20-23.605,8%20-33.5,8%20-34.125,0%20-55.5,-19.341%20-55.5,-50%200,-30.784%2021.128,-50%2055.5,-50%20m%20-103.5,2.5%20h%2022%20v%2095%20h%20-22%20z%20M%20-536,-50%20c%2027.127,0%2042,11.809%2042,30.326%200,23.018%20-24.358,28.393%20-43.5,31.7%20-13.347,2.306%20-23,4.28%20-23,10.8%200,5.697%206.895,8.092%2021.673,8.092%2013.023,0%2027.965,-2.697%2040.327,-7.592%20l%20-1,21%20C%20-515.737,49.045%20-526.907,50%20-539,50%20c%20-26.578,0%20-43,-10.415%20-43,-27.122%200,-22.856%2023.488,-27.807%2042.038,-31.027%2013.246,-2.343%2024.462,-4.36%2024.462,-12.006%200,-8.118%20-10.957,-10.019%20-20.5,-10.019%20-15.487,0%20-27.243,4.543%20-45.5,13.674%20l%201,-22.5%20c%2015.24,-7.948%2031.788,-11%2044.5,-11%20m%2077.5,2.5%20h%2022%20v%2095%20h%20-22%20z%20m%2060.5,95%20h%2021%20l%2055,-63.5%20v%2063.5%20h%2022%20v%20-95%20h%20-21%20L%20-376,16%20v%20-63.5%20h%20-22%20z'%20style='fill:%23000000;fill-opacity:1;fill-rule:nonzero;stroke:none'%20id='path132'%20/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
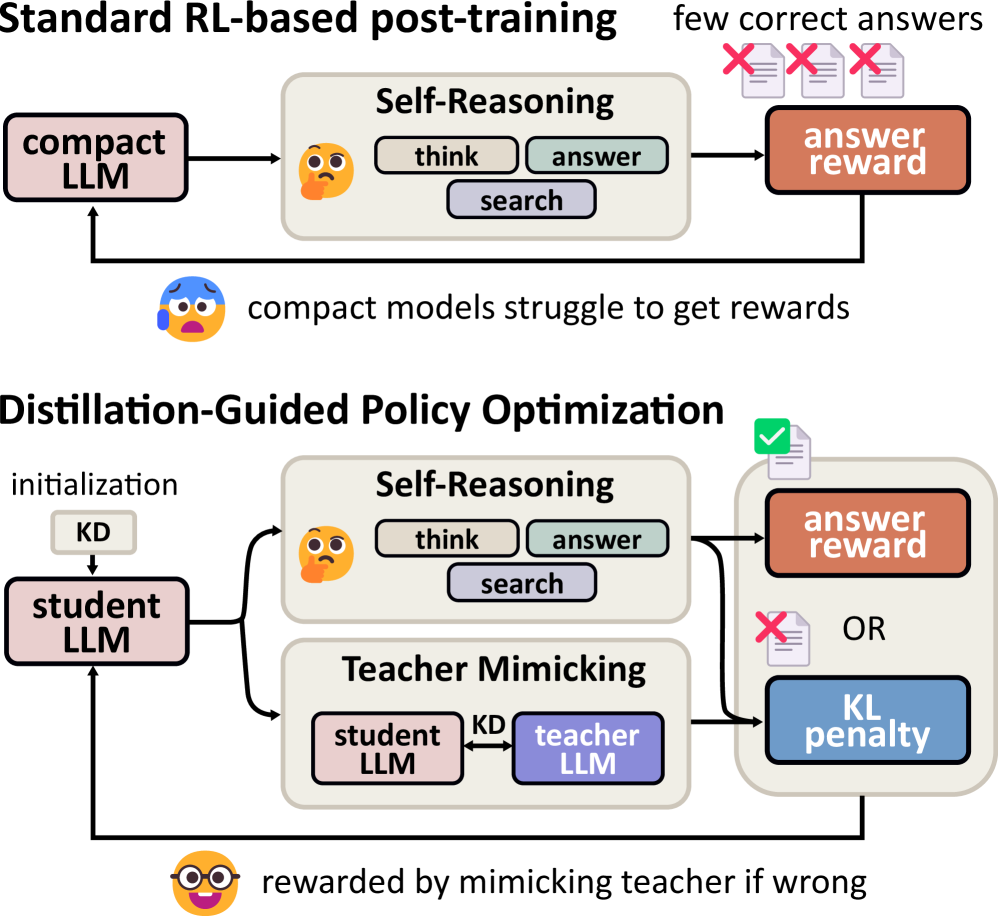
TL;DR We investigate whether compact language models (0.5–1B) can acquire sophisticated agentic retrieval-augmented generation (RAG) behavior. While existing agentic RAG systems rely on multi-billion-parameter models, compact models suffer from poor initial outputs, sparse rewards, and unstable reinforcement learning dynamics. To address these challenges, we propose Distillation-Guided Policy Optimization (DGPO), a two-phase training framework combining cold-start knowledge distillation and selective teacher-guided reinforcement learning.
Overview
This project introduces Distillation-Guided Policy Optimization (DGPO), a reinforcement learning framework designed to unlock agentic retrieval-augmented generation (RAG) capabilities in compact language models (0.5–1B parameters). DGPO stabilizes training via:
- Cold-Start Initialization with Knowledge Distillation (KD) using high-quality teacher-generated trajectories.
- Selective Teacher Guidance during RL—rewarding correct autonomous reasoning while penalizing incorrect outputs via KL divergence against the teacher.
DGPO achieves up to 55× improvement over base compact models and even surpasses its 3B-parameter teacher on several datasets.
Challenges in Compact Agentic RAG
Applying Reinforcement Learning (RL) to compact models presents unique challenges. Unlike larger models, compact models (e.g., 0.5B parameters) exhibit poor initial performance, resulting in sparse rewards and unstable training dynamics.
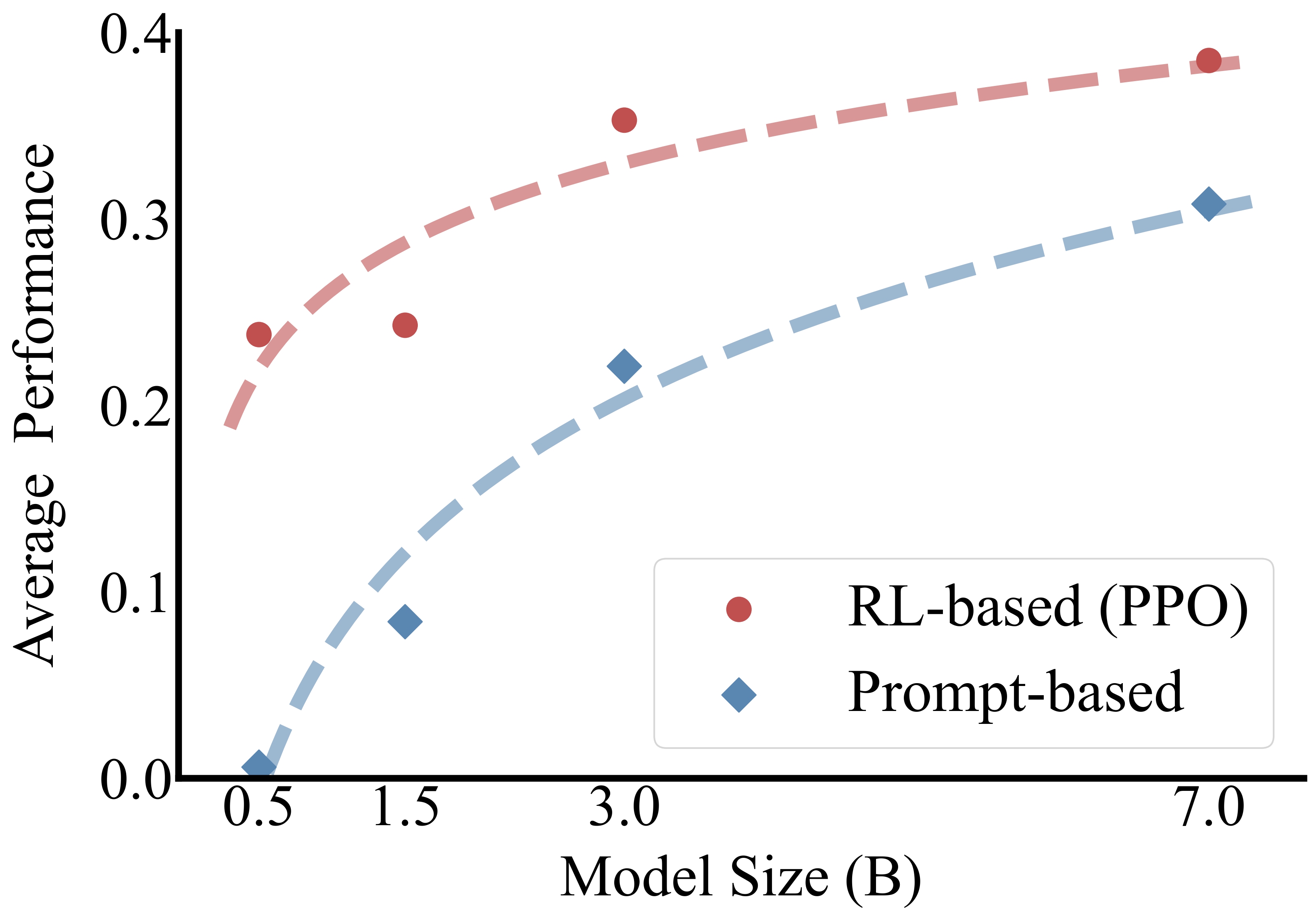
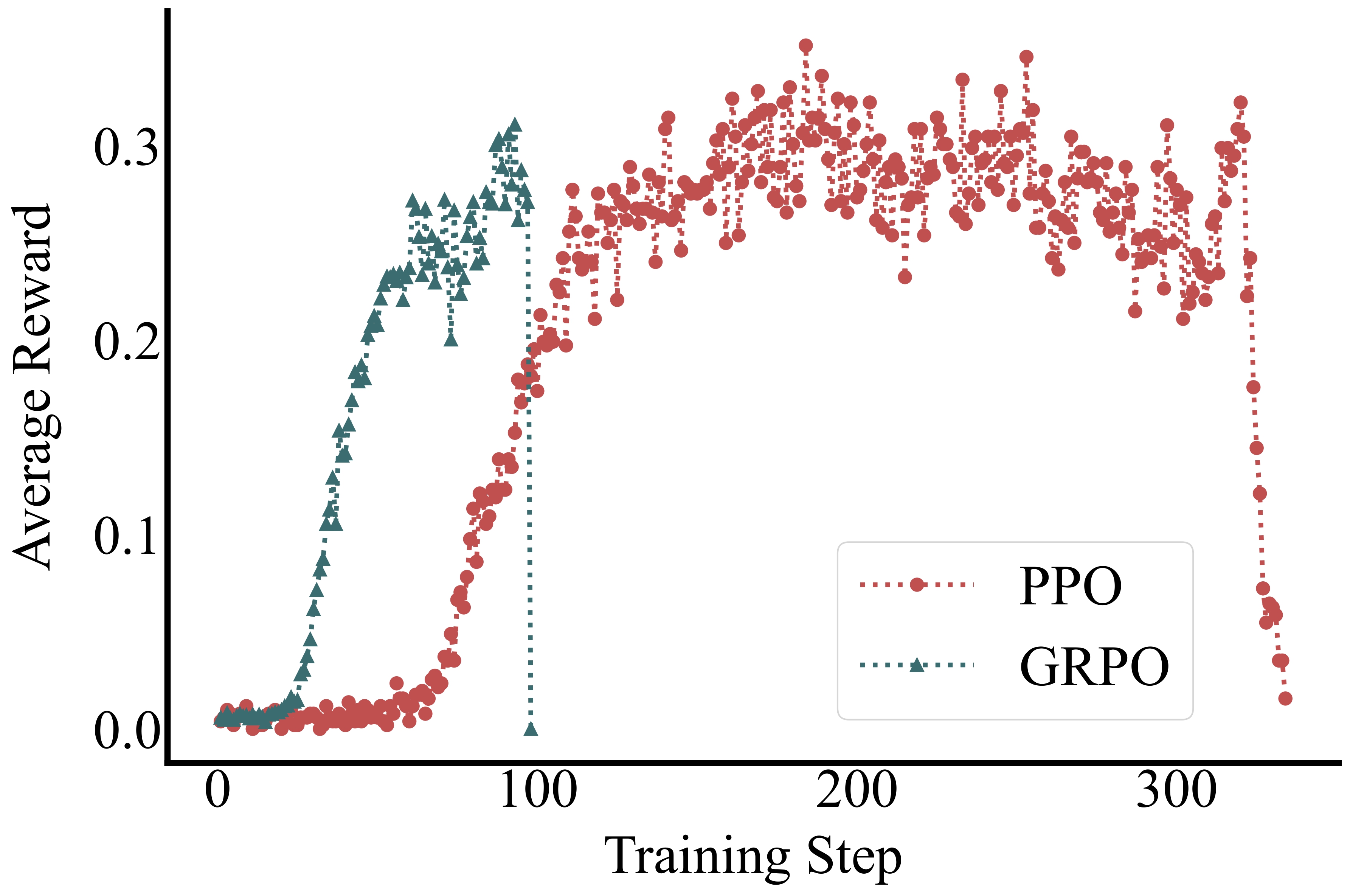
As shown in the figures below, smaller models lag significantly behind larger counterparts in agentic RAG tasks, and standard RL methods like PPO and GRPO often fail to improve performance or lead to early collapse.
Distillation-Guided Policy Optimization (DGPO)
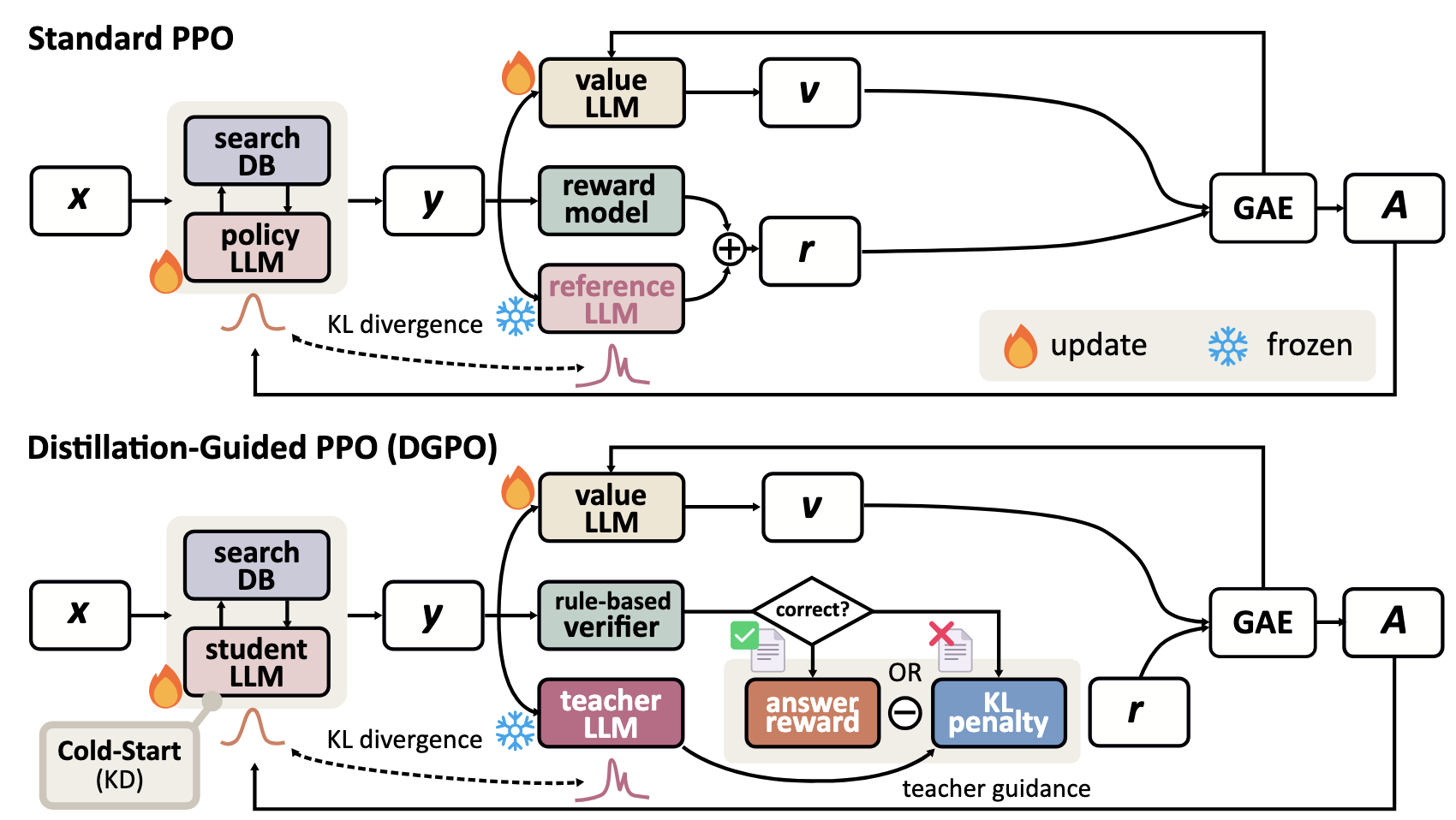
To overcome these challenges, we propose Distillation-Guided Policy Optimization (DGPO). Our framework operates in two key phases:
- Cold-Start KD Initialization: The student model is initialized by distilling from a teacher's correct trajectories (TGOs). This establishes a stable foundation for reasoning.
- Distillation-Guided RL: We employ a "mimic if wrong, reward if right" strategy.
- Correct Answer: The student receives a reward (r=1) and updates its policy autonomously.
- Incorrect Answer: The student is penalized via KL divergence to mimic the teacher's distribution, effectively using the teacher as an active guide for error correction.
The core of DGPO lies in its selective reward and penalty mechanism during the RL phase:
This objective allows the student to explore when confident but forces alignment with the teacher when it fails.
Agentic RAG Capabilities (ARCap) Evaluation
We introduce Agentic RAG Capabilities (ARCap), a fine-grained metric to diagnose how models perform agentic search, rather than just checking final answer accuracy. ARCap evaluates three dimensions:
- Thinking: The ability to plan search steps and synthesize evidence.
- Query Rewriting: The ability to reformulate user questions into effective search queries.
- Source Referencing: The ability to accurately cite and integrate retrieved documents.

Experimental Results
Overall Performance
We evaluated DGPO across seven benchmarks. DGPO consistently outperforms RL baselines (PPO) and distillation baselines. Remarkably, the 0.5B student model trained with DGPO approaches or even surpasses the 3B teacher model on datasets like NQ and HotpotQA.
| Methods | NQ | TriviaQA | PopQA | HotpotQA | 2wiki | MuSiQue | Bamboogle | Avg. |
|---|---|---|---|---|---|---|---|---|
| 🐣 Student-0.5b | 0.004 | 0.006 | 0.007 | 0.007 | 0.015 | 0.000 | 0.000 | 0.006 |
| 🎓 Teacher-3b | 0.365 | 0.569 | 0.393 | 0.340 | 0.368 | 0.135 | 0.298 | 0.353 |
| PPO | 0.306 | 0.444 | 0.379 | 0.205 | 0.218 | 0.041 | 0.073 | 0.238 |
| GKD | 0.266 | 0.408 | 0.358 | 0.216 | 0.217 | 0.055 | 0.161 | 0.240 |
| SeqKD | 0.331 | 0.416 | 0.364 | 0.283 | 0.273 | 0.089 | 0.169 | 0.275 |
| KD | 0.331 | 0.431 | 0.373 | 0.286 | 0.284 | 0.091 | 0.290 | 0.298 |
| DistiLLM | 0.333 | 0.442 | 0.373 | 0.288 | 0.270 | 0.095 | 0.209 | 0.287 |
| TAID | 0.325 | 0.427 | 0.365 | 0.290 | 0.270 | 0.079 | 0.218 | 0.282 |
| DGPO (ours) | 0.378 🏅 | 0.481 | 0.402 🏅 | 0.342 🏅 | 0.303 | 0.120 | 0.274 | 0.329 |
Agentic RAG Capabilities (ARCap) Analysis
We utilized the ARCap framework to diagnose how DGPO improves agentic behaviors compared to the teacher and baselines.
- (a) Source Referencing: DGPO provides strong information extraction when the correct evidence is directly available.
- (b) Query Rewriting: DGPO achieves teacher-level query rewriting.
- (c) Thinking: DGPO exhibits the strongest multi-hop reasoning by taking more search steps than the teacher model.
| Models | NQ (Single-hop) | MuSiQue (Multi-hop) | ||
|---|---|---|---|---|
| w/o think | w/ think | w/o think | w/ think | |
| Student-0.5B | 0.386 | 0.034 | 0.166 | 0.013 |
| Teacher-3B | 0.589 | 0.560 | 0.413 | 0.357 |
| PPO | 0.547 | 0.581 | 0.258 | 0.242 |
| KD | 0.540 | 0.544 | 0.321 | 0.256 |
| DGPO (Ours) | 0.565 | 0.593 | 0.312 | 0.287 |
| Models | NQ (1-hop) | MuSiQue (Multi-hop) | |
|---|---|---|---|
| Hit Ratio | Hit Ratio | Search Steps | |
| Student-0.5B | 0.004 | 0.052 | 3.86 |
| Teacher-3B | 0.682 | 0.668 | 1.60 |
| PPO | 0.711 | 0.568 | 1.68 |
| KD | 0.675 | 0.570 | 2.45 |
| DGPO (Ours) | 0.682 | 0.583 | 2.64 |
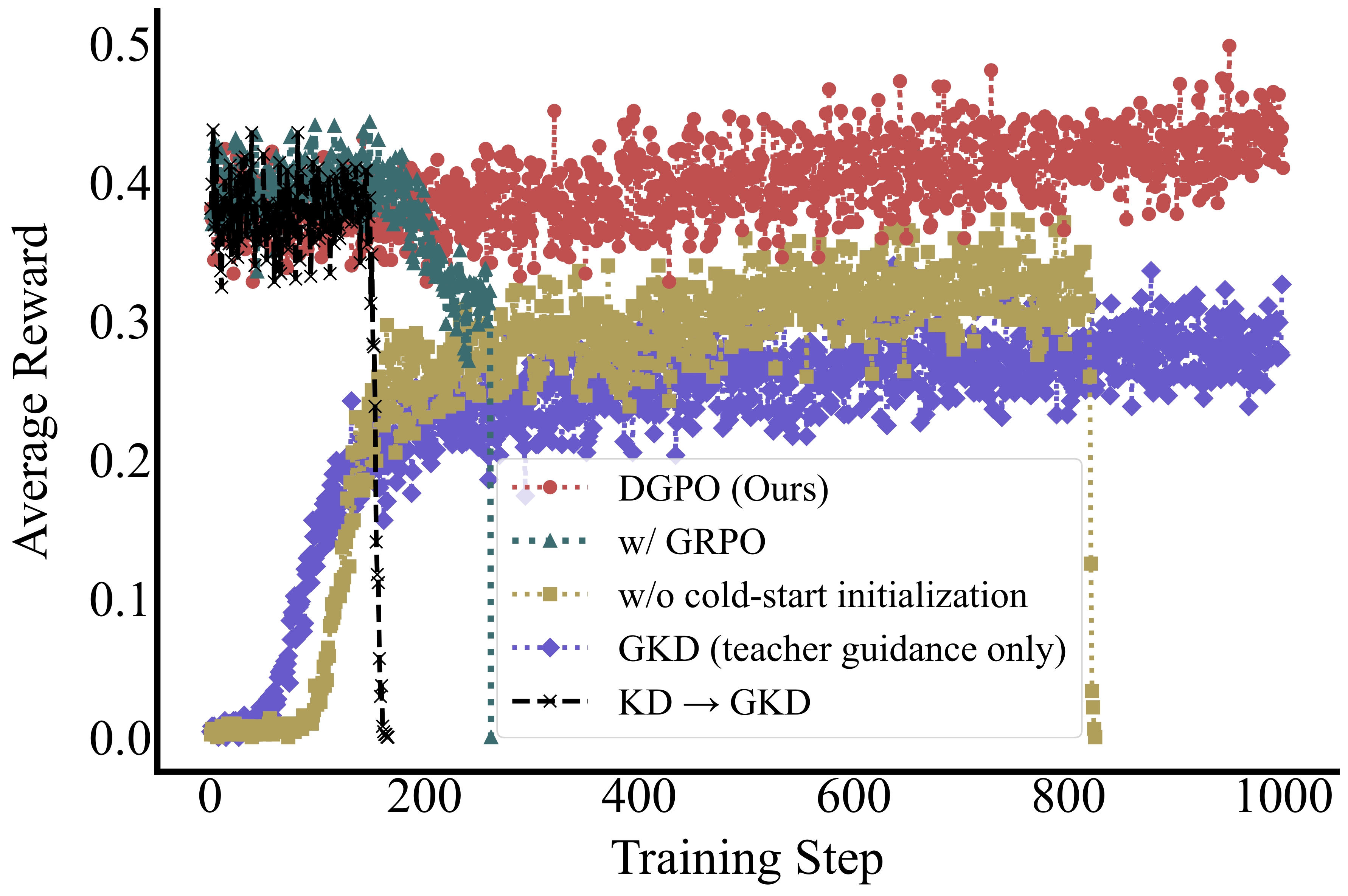
Training Stability
DGPO maintains stable learning curves well beyond where other methods collapse. As shown below, while GRPO and standard PPO struggle with the 0.5B model, DGPO sustains performance gains up to 1000 training steps.
Acknowledgement
This work was supported by JST AIP Acceleration Research, Japan, Grant Number JPMJCR23U2 and JST PRESTO, Japan, Grant Number JPMJPR2518.
Contact
Citation
@inproceedings{kotoge2026dgpo,
title = "Can Compact Language Models Search Like Agents? Distillation-Guided Policy Optimization for Preserving Agentic RAG Capabilities",
author = "Kotoge, Rikuto and Nishimura, Mai and Ma, Jiaxin",
booktitle = "Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2026",
publisher = "Association for Computational Linguistics",
}
@inproceedings{kotoge2025democratizing,
title = "Democratizing Agentic {RAG}: Distillation-Guided Policy Optimization for Compact Language Models",
author = "Kotoge, Rikuto and Nishimura, Mai and Ma, Jiaxin",
booktitle = "NeurIPS 2025 Workshop on Bridging Language, Agent, and World Models for Reasoning and Planning",
year = "2025",
url = "https://openreview.net/forum?id=CP0H9NAWES",
}